





Journey to a Faster Concurrent Map
Maps, maps everywhere
- Buzz Lightyear (inaccurate citation)
Maps, also known as dictionaries, or associative arrays, are one of the oldest (hash tables are almost 70 years old) and the most important data structures. You may find them in almost every program regardless of the programming language and Golang is not an exception here. Any gopher also knows that it’s trivial to build a set on top of a map proving that maps are quite versatile.
Concurrent maps are a less frequent guest in a Go application when compared with the basic non-goroutine-safe map. Yet, I’m pretty sure that most of the readers wrote something similar to the following code to protect a map with an ordinary or readers-writer mutex:
func main() {
type rwmap struct {
data map[int]int
mu sync.RWMutex
}
m := rwmap{data: make(map[int]int)}
for i := 0; i < 10; i++ {
go func(nreader int) {
m.mu.RLock()
j, ok := m.data[nreader]
// ...
m.mu.RUnlock()
}(i)
}
// ...
}
While such a mutex-protected map has the advantages of low memory footprint and implementation simplicity, its performance leaves much to be desired. Even the RWMutex variant of this concurrent map does not scale in terms of reads, needless to say about writes.
If you’re interested in the details, the reason for that is poor CPU core-wise scalability of the atomic.AddInt32() function used on the reader fast path in RWMutex. This function boils down to an atomic increment instruction available in modern CPUs, e.g. LOCK XADD on x86. The aforementioned instruction implies exclusive access to the counter (the corresponding cache line, to be more precise) acquired by the CPU core executing the caller goroutine. Hence, the increment is still restricted with a single writer core and, to add on top of that, in the face of contention the synchronization cost paid by each core increases significantly. Refer to this comprehensive blog post by Travis Downs to learn more on the cost of concurrency primitives on modern HW.
You could also have used sync.Map which does a much better job on the read scalability but has the same single writer restriction. The great read scalability of this map implementation can be explained by the fact that read operations imply no writes to shared memory done on the fast path. However, writing to new keys or deleting the existing ones in sync.Map is quite expensive making it suitable for niche use cases only. Not surprisingly, godoc for this map has the following notice:
The Map type is optimized for two common use cases: (1) when the entry for a given key is only ever written once but read many times, as in caches that only grow, or (2) when multiple goroutines read, write, and overwrite entries for disjoint sets of keys. In these two cases, the use of a Map may significantly reduce lock contention compared to a Go map paired with a separate Mutex or RWMutex.
So, both of the widely spread approaches to concurrent maps in Golang have a number of performance problems. The question is whether we can build something that has better scalability characteristics while keeping the spirit of Go’s simplicity in the implementation. Let’s find out!
Prior Art
Before going any further, make sure that you’re familiar with the basics of hash tables.
Concurrent hash tables are not something new and there are a bunch of implementations and academic studies focused on new algorithms or improvements to the existing ones. The latter usually focus on non-blocking behavior (lock- or even wait-freedom) for map operations. As an illustration of recent work done in the field, I’d point curious readers at the Concurrent Robin Hood hash table paper which describes a way to build a concurrent non-blocking algorithm based on the Robin Hood hashing. The proposed algorithm is fairly complex and has a number of benefits, including solid performance, yet it doesn’t describe rehashing (think, hash table resizing), a critical part of a general-purpose concurrent map. The reason is that non-blocking rehashing is very tricky.
One of the first successful implementations of a fully non-blocking hash table I’m aware of is Cliff Click’s NonBlockingHashMap. You may learn how this map is designed in this talk. The source code may be found in JCTools library. If you check the code, you might find it a bit complicated and I’m all with you here. The thing is all fully non-blocking hash table algorithms I found are more or less complex.
Does all of this mean that we’ve lost the quest for a faster concurrent map? Not really. The thing is that you don’t really need to go fully non-blocking to get better scalability. As Dmitry Vyukov explains in this blog post, terms like lock- or wait-freedom stand for forward progress guarantees and are orthogonal to performance. Of course, there are examples of non-blocking algorithms that are faster than blocking ones, but that’s not a law. Let’s try to do a wider look around.
It turns out that a concurrent map can be fast if it has the following two properties:
- Read operations don’t involve writing to shared memory. This automatically means a non-blocking algorithm is used for reads.
- Write operations to avoid contention most of the time. This can be achieved with sharding, i.e. using separate mutexes to protect individual hash table buckets instead of a single one.
Java’s ConcurrentHashMap is a good example of such a concurrent hash map. For instance, it performs very well against the NonBlockingHashMap data structure. There is even a Rust port of this data structure. On the other hand, ConcurrentHashMap organizes its entries in linked lists (and optionally in binary trees) and we might want to use something with a more optimal memory layout to benefit from Golang’s strong points.
Luckily, there are other algorithms that have the properties we need. Cache-Line Hash Table (CLHT) is one of them. You may find its C lang implementation here. The core idea is to have bucket data fit a single cache-line, so the number of cache lines that are being written when performing writes on the map is reduced. This helps with minimizing the amount of generated coherence traffic.
CLHT comes in multiple flavors, but we should be fine with the one that has blocking writes. Apart from that, we need to change the algorithm in order to make it suitable for a general-purpose concurrent map. We’ll see how the tweaked algorithm looks in the next section.
Meet xsync.Map
First of all, the API of our concurrent map will follow the one in sync.Map with one difference. Since, we’re talking of a user-land implementation, supporting arbitrary types for keys, especially when it comes to structs, is tricky. That’s why we’re going to support string keys only while values will be of arbitrary type, i.e. interface{}. So, dealing with our map would look something like this:
m := xsync.NewMap()
m.Store("foobar", 42)
v, ok := m.Load("foobar")
Second, we need a fast hash function. Here we can simply use the memhash internal runtime function which is also exposed via the hash/maphash standard package.
Now, we’re ready to discuss the algorithm itself. The underlying hash table will be represented as a slice of bucket structs. Each of these structs looks like the following.
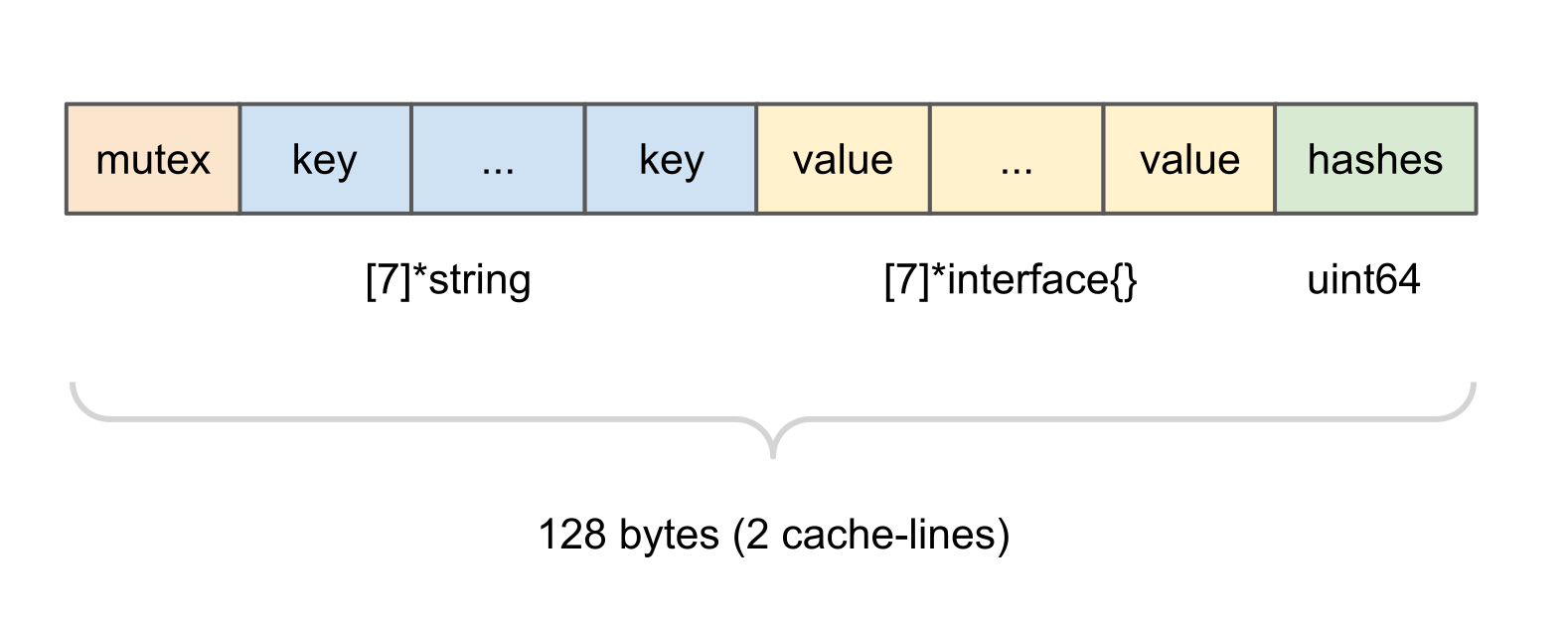
Here we have 128 bytes (two cache-lines on most modern CPUs) holding a sync.Mutex, 7 key/value pairs, and a uint64 with cached hash codes for the keys present in the bucket. The mutex is being used while writing to the bucket. The key/values pairs hold pointers to the map entries. Finally, the hash code cache holds one most significant byte per each key’s hash code.
You may also notice that the original CLHT algorithm uses a single cache-line while we’re using two of them. That’s because we want to cache hash codes in order to avoid extra calculations while doing lookups. We also want to store more than 3 entries per bucket like it was in the original algorithm. Finally, some CPUs, like Intel ones, have adjacent cache-line prefetch in place, so they load two cache-lines in any case.
While write and hash table resizing operations are more or less straightforward, we’d wanted to have non-blocking reads. CLHT has a so-called atomic snapshot to do that. The goal is to read both key and value pointers from the bucket in an atomic manner, i.e. no writes should occur in between while we’re reading these pointers. An important aspect of the atomic snapshot algorithm is that it requires pointers to map values to be unique. That’s what we in fact have when using empty interfaces for values. Each *interface{} points to an implicit struct that holds the type information and the pointer to the actual value (refer to this blog post to learn more). On the other hand, Golang has a non-moving garbage collector. Hence, all live empty interface pointers are guaranteed to have unique addresses.
There is one more problem to be solved in reads. CLHT has “store if absent” semantics for store operation, i.e. a value would be stored if there is no entry with the same key in the map. But if we downgrade wait-freedom for reads to lock-freedom by adding an extra retry logic in place, reads will work in a general-purpose way.
Simplified atomic snapshot code looks something like this:
func (m *Map) Load(key string) (value interface{}, ok bool) {
// Hash function call, reading the bucket, and so on go here.
// …
for i := 0; i < entriesPerMapBucket; i++ {
atomic_snapshot:
vp := atomic.LoadPointer(&b.values[i])
kp := atomic.LoadPointer(&b.keys[i])
if kp != nil && vp != nil {
if key == derefKey(kp) {
if uintptr(vp) == uintptr(atomic.LoadPointer(&b.values[i])) {
return derefValue(vp), true // Atomic snapshot succeeded.
}
goto atomic_snapshot // Concurrent update/remove.
}
}
}
return nil, false
}
The idea behind the above is very simple. For each bucket item, we do an atomic snapshot attempt: first, we read the value pointer, then the key pointer, and, finally, if the key is the one we’re looking for, we read the value pointer once again. As long as live value pointers are guaranteed to be unique, seeing the same value pointer address means that no write happened in between and that the snapshot is successful.
The rest of the implementation details may be seen in the xsync library. Enough of boring concurrent algorithms, let’s jump to the benchmark fun.
Lies, Damned Lies, and Microbenchmarks
A few words on the methodology for the (totally non-scientific) benchmarks. The results were obtained on a GCP e2-highcpu-32 VM with 32 vCPUs (Intel Haswell), 32 GB RAM, Ubuntu 20.04, Go 1.16.5. Each benchmark was run several times to obtain an average.
The first scenario is a “read-heavy” one. Concurrent goroutines do 99% Load, 0.5% Store, 0.5% Delete operations over randomly selected keys. The map is warmed-up with one million entries. The below chart shows how xsync.Map does against sync.Map.
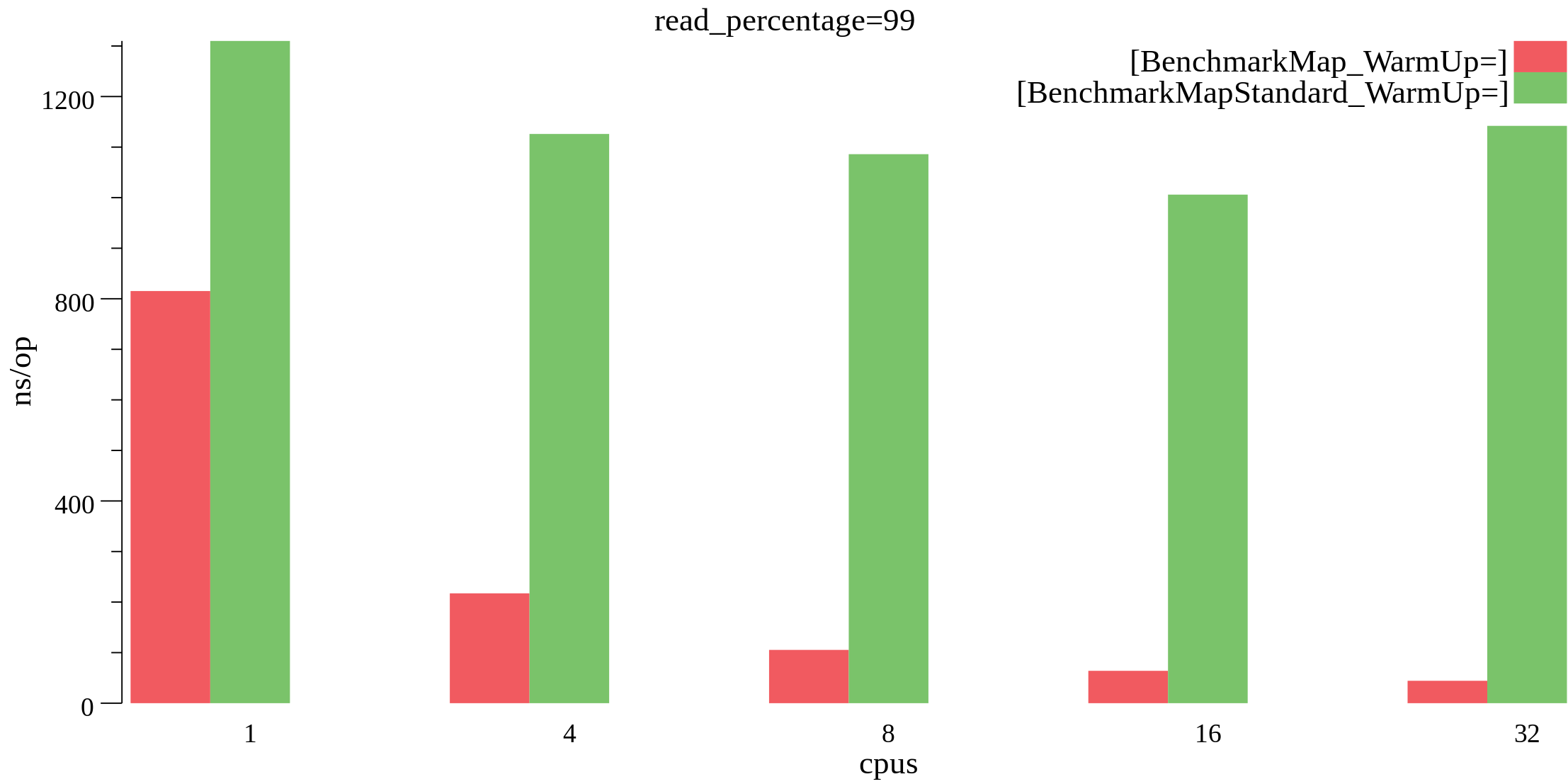
A clear win for xsync.Map. What’s even more important, it shows almost linear scalability in terms of CPU core count.
Let’s see what we have for 90% Load, 5% Store, 5% Delete operations.
Finally, a “write-heavy” benchmark: 75% Load, 12.5% Store, 12.5% Delete operations.
Hopefully, the results demonstrate that xsync.Map is more versatile than sync.Map.
What’s Next?
As with everything in software engineering, xsync.Map is not a silver bullet. It has some drawbacks, some of which could be improved. Since it’s available in an open source library, contributions are welcome.
Is it the end of our journey? Probably not. There is a small chance that xsync.Map finds its way into the Golang standard library as a replacement for sync.Map.
Thanks for reading the blog post!