





Dependency Injection for Golang Developers
Somewhere in the last few years, I feel a piece of our community wasn’t so concerned about engineering good practices, it may be derived by grown of microservices architecture, we may have thought we could always rewrite everything easily. It may be true, but in practice, you don’t want to spend time rewriting code, you want write new code, new products, especially if you’re working in hyper-growth company. That’s why good practices are important, they keep your software maintainable through time. I’d like to show you how Dependency Injection could help you with that.
What is Dependency Injection?
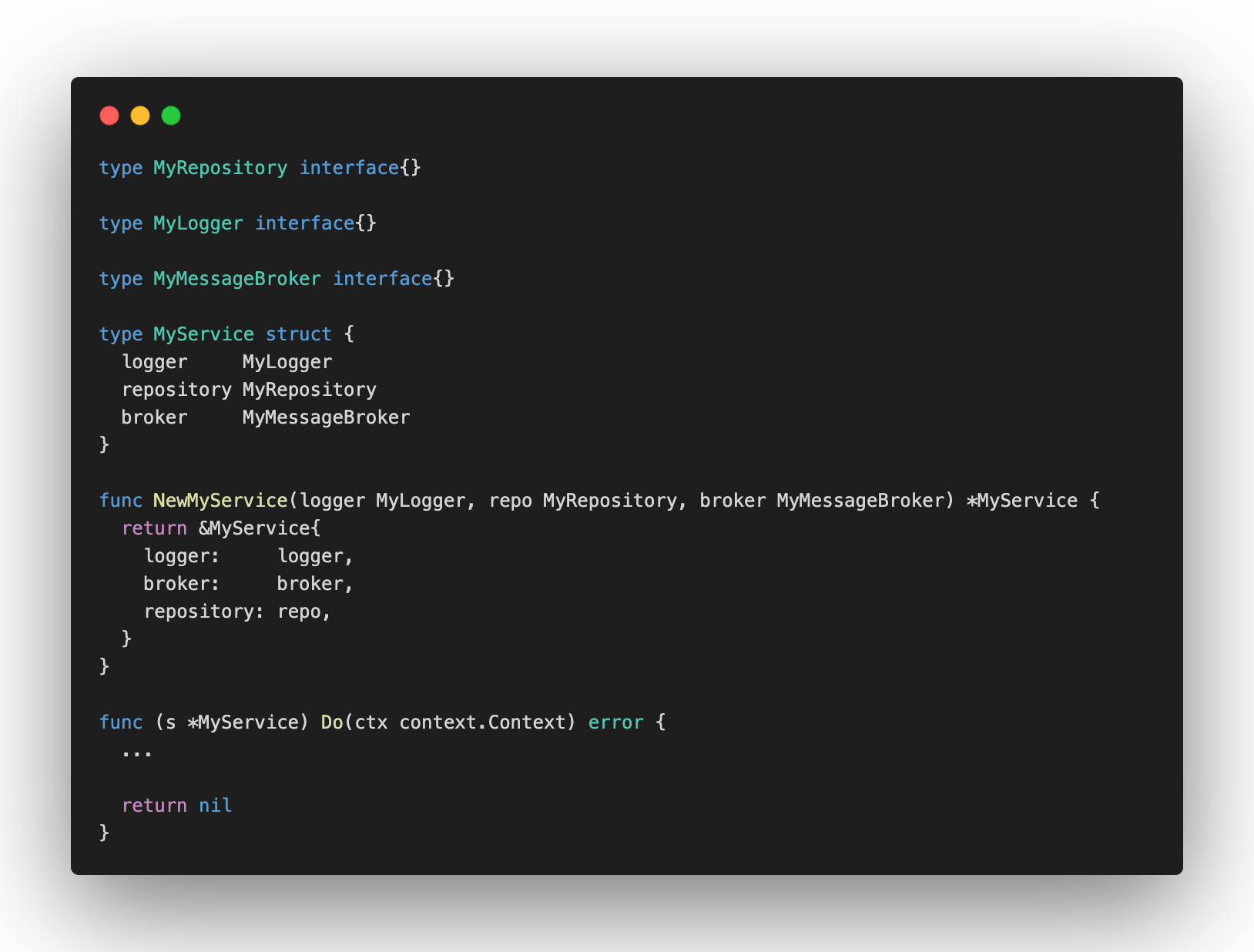
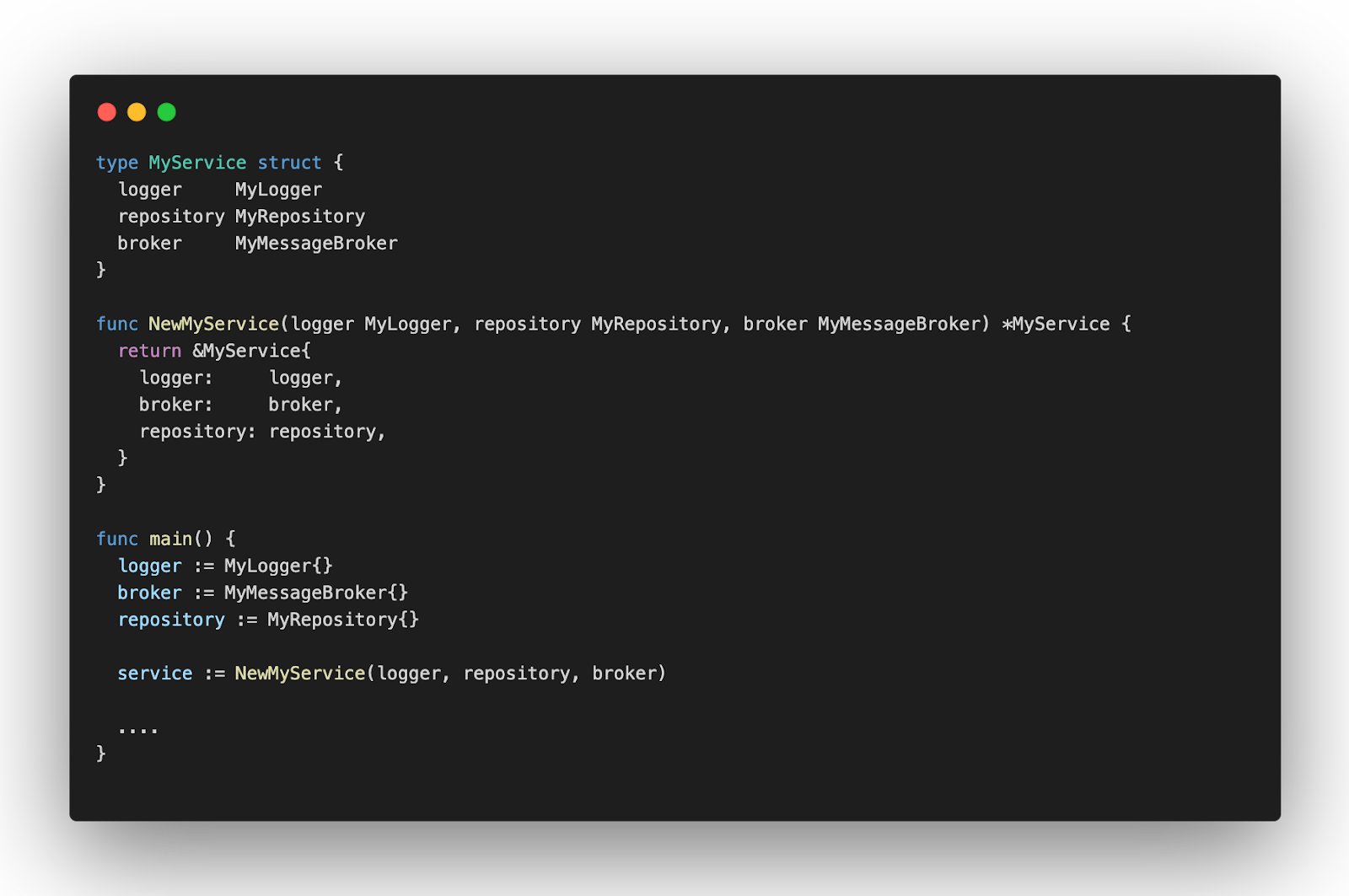
Dependency Injection is a design pattern, that helps you to decouple the external logic of your implementation. It’s common an implementation needs an external API, or a database, etc. It isn’t responsibility of the implementation to know these things, it should receive its dependencies and use them as it needs. Let’s say you have an implementation with the dependencies below.
You could just create the dependencies and set them into your Service/Use case. But it would be bad especially for testing, how would you change the behavior of an external service? Or a database? You can’t. Your only option is to write an integration test instead of unit tests.

An important point of injecting dependencies is to avoid injecting implementations (structs), you should inject abstractions (interfaces). It’s the letter D of S.O.L.I.D: Dependency Inversion Principle. It allows you to switch easily the implementation of some dependency and, you could change the real implementation for a mock implementation. It’s fundamental for unit testing.
Kinds of Dependency Injection
There are some kinds of dependency injection, and each one has its own use case. Here we’ll cover three of them: Constructor, Property and, Method (or Setter).
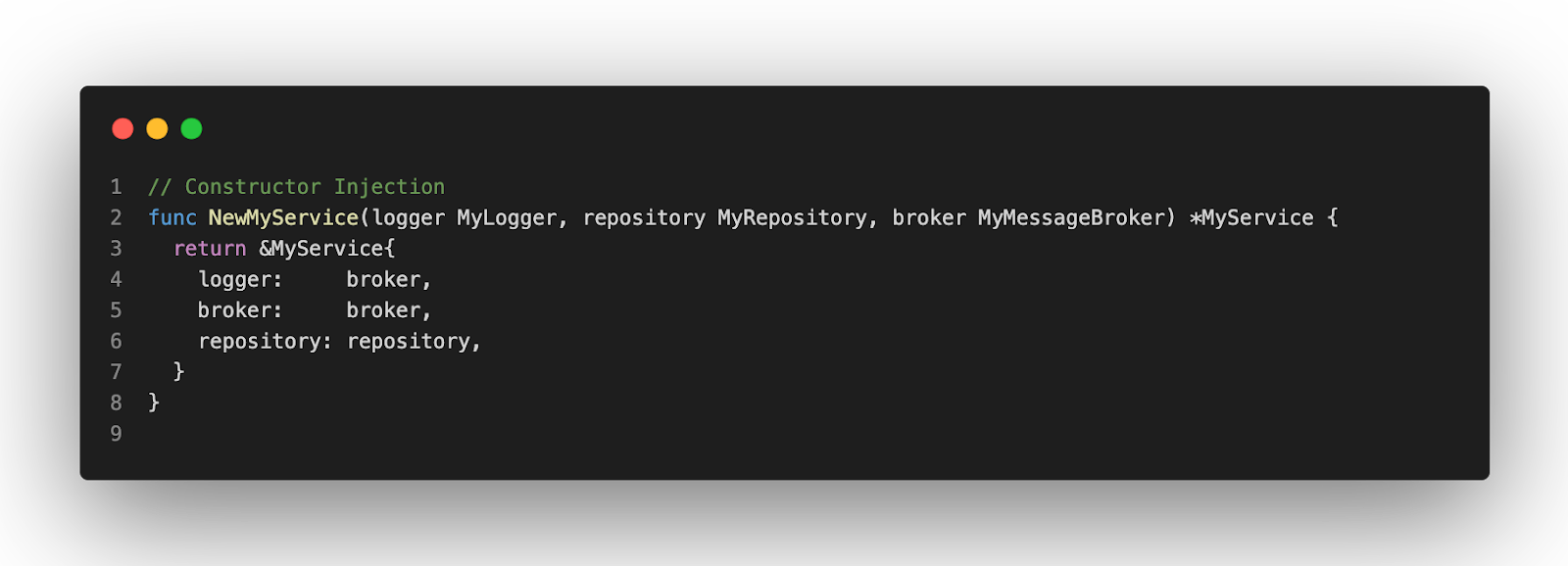
The most common kind is the Constructor Injection. It allows you to make your implementation immutable, nothing can change the dependencies (if your properties are private). Also, it requires all dependencies to be ready to create something. If they aren’t, it usually will generate an error.
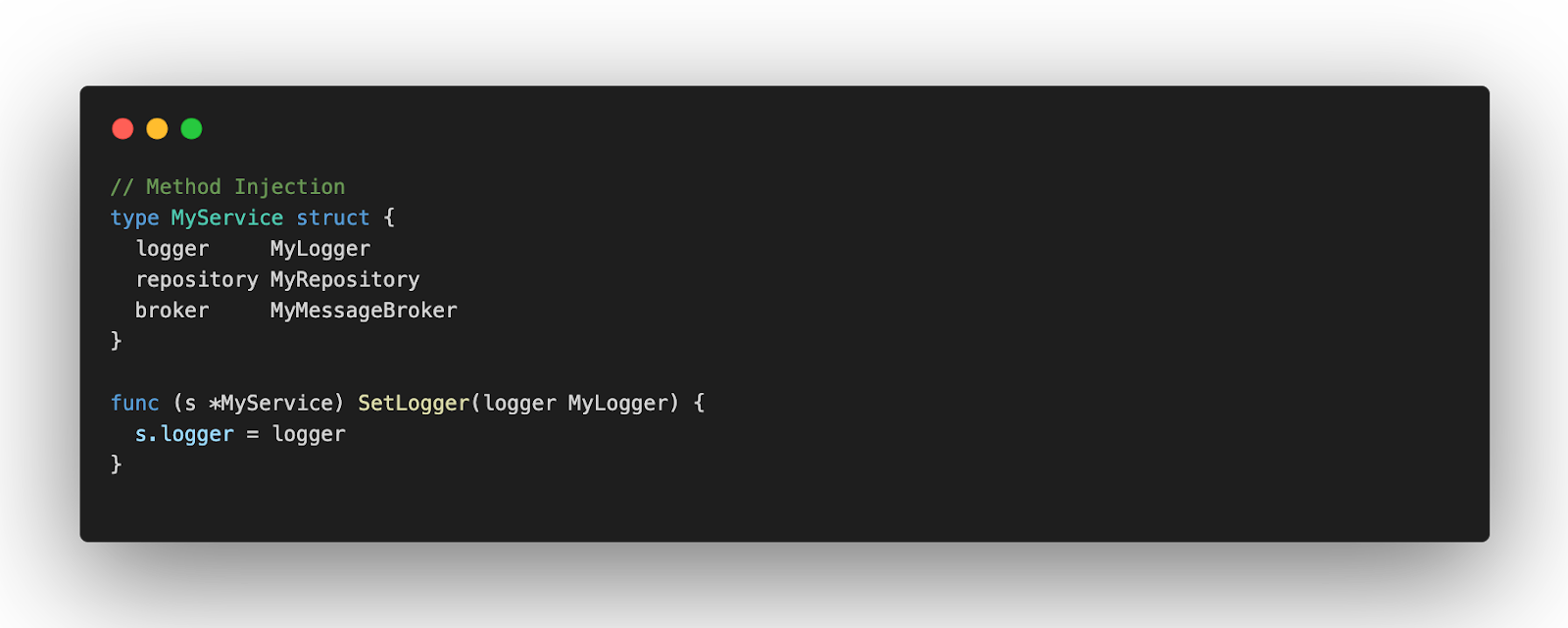
Property and Method injection are pretty similar, I think their adoption is a question of a language feature. In Java is more common to have Method Injection, and in C# is more common to have Property Injection. In Go, we will see the usage of both. These kinds allow you to change dependencies in runtime, so by design, they aren’t immutable. But if you need to change the implementation of some dependency, you don’t need to recreate everything. You can just override what you need. It may be useful if you have a feature flag that changes an implementation inside your service.
How do I do it?
There are two main ways to get it done in practice. The first one is manually, and the other (and prettier) is using a dependency injection container.
Manually
Manually construction is an objective way to do it. You declare, create, and inject your dependencies step by step. I think it’s clean and there isn’t any magic happening behind the scenes. The problem is as your dependencies get complex you need to deal with complexity by yourself. You may see your func main() getting with hundreds of lines of code and harder to mantein.
Container
In a container style, you’ll need to teach your container how to create a dependency and then it’ll create your dependency graph to discover how to create dependencies. Once you ask for a dependency, it’ll follow the graph creating everything related to it. Let’s imagine a scenario where we need to create two Services/Use cases, and they have dependencies between them and across them:
Once you’ve teached your container how to create each dependency, it’ll create a dependency graph, which would be something like that:
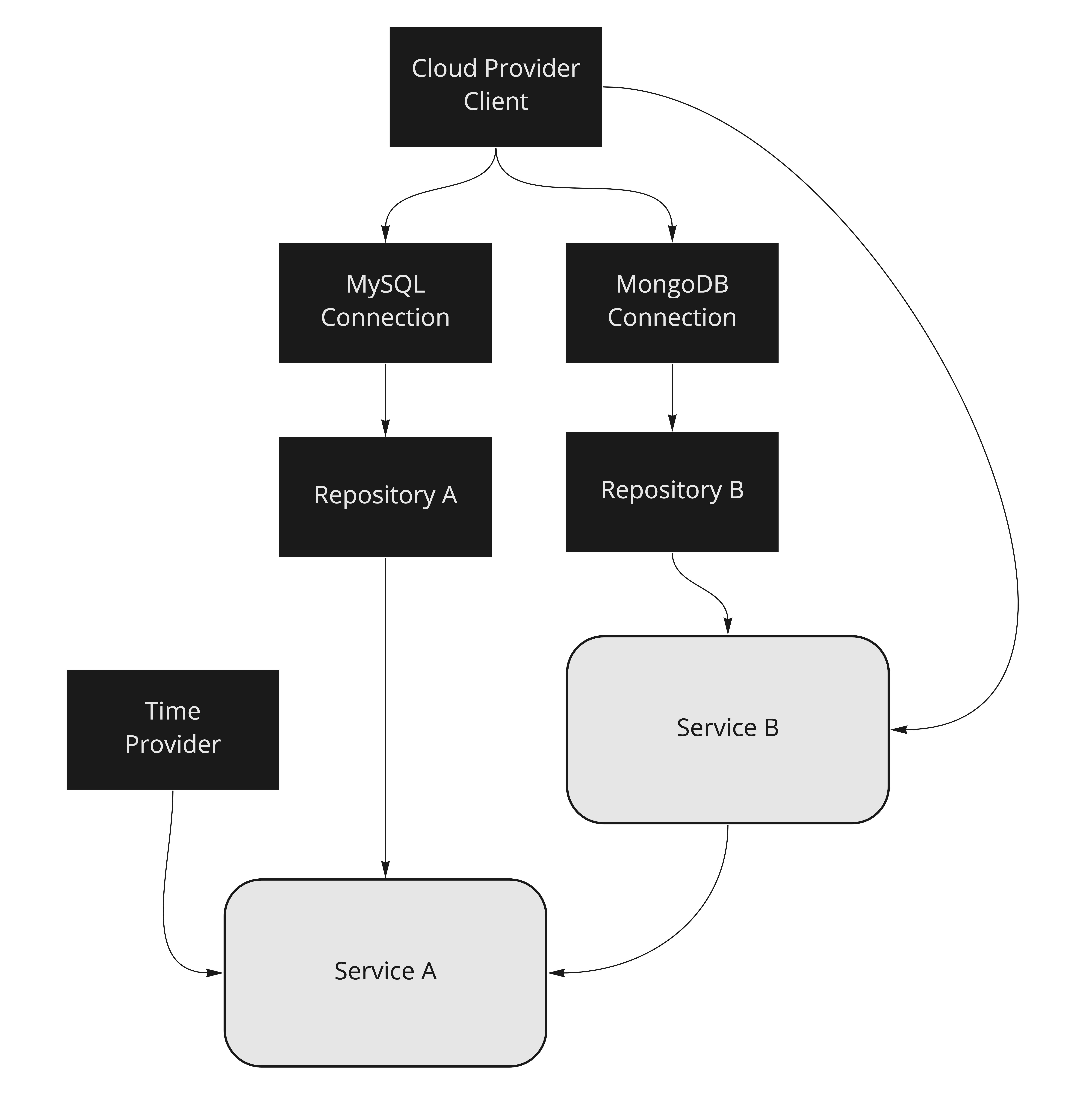
If you’ve chosen the manual style, imagine this scenario getting bigger and bigger. Imagine all of your services doing the same startup process. It’ll get complex to deal with in long term.
uber-go/dig is a dependency injection toolkit developed by Uber to resolve this kind of problem, with reflection. It’s really powerful and helps you to reduce the code you write to setup your service. It’s important to say it’s focused on the application startup, there are other containers such sarulabs/di, that may also deal with dependency lifecycle (e.g. one instance per request). If you’re interested in this kind of dependency injection, take a look at it. By design, uber-go/dig understands that everything is a Singleton and it’ll create your dependencies just once.
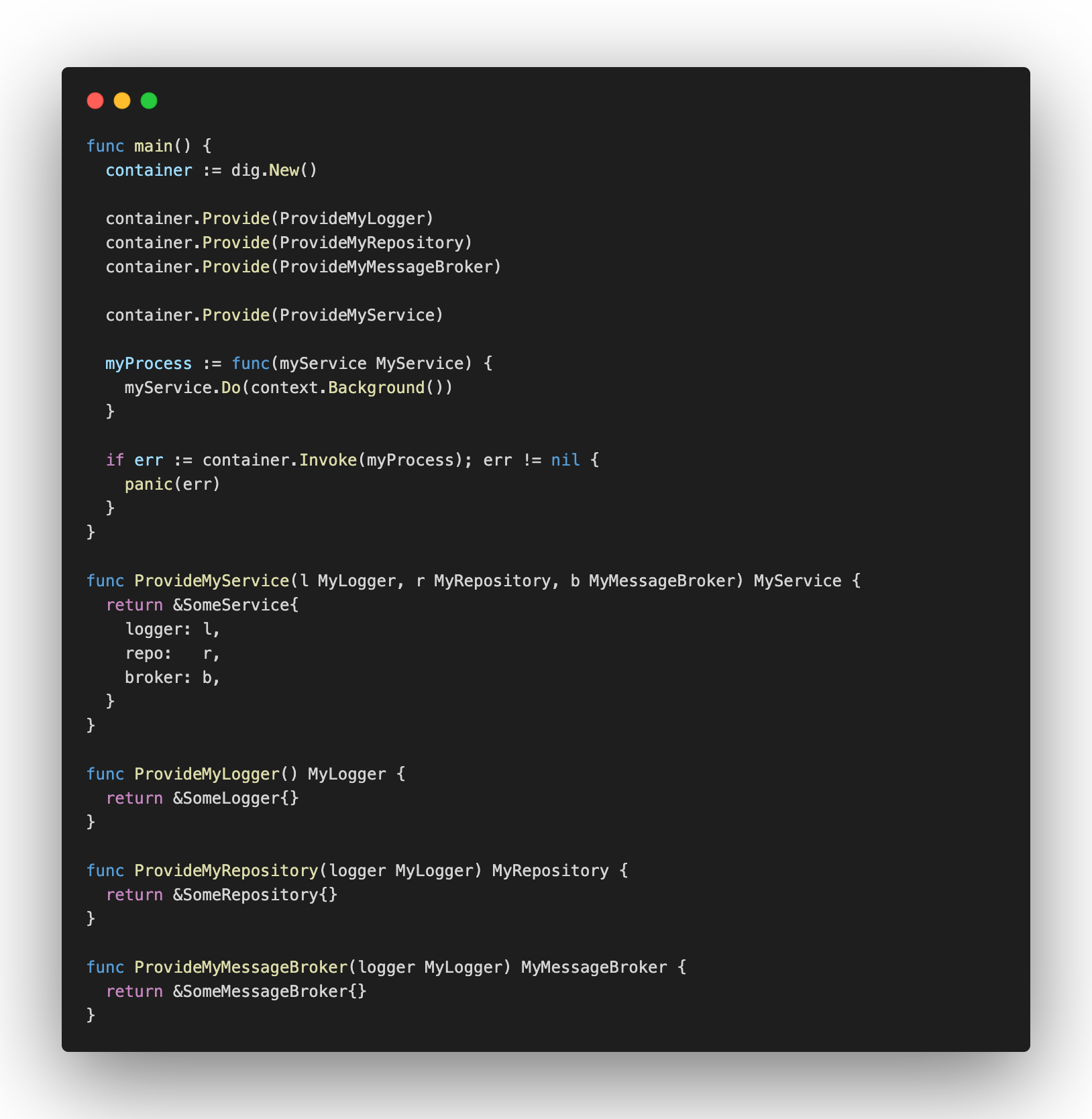
All parameters for uber-go/dig are interface{}, but you can’t pass what you want. It must be a func that receives N parameters and it may return N results too, also an error. By reflection, it reads the type of each parameter your func receives and returns, and with that, it can build the dependency graph we discussed above. If some func returns an errors, it’ll return an error when you try to call it too. It’s useful if you tried to connect to some database and it isn’t up.
Using Constructor Injection, we could write something like that:
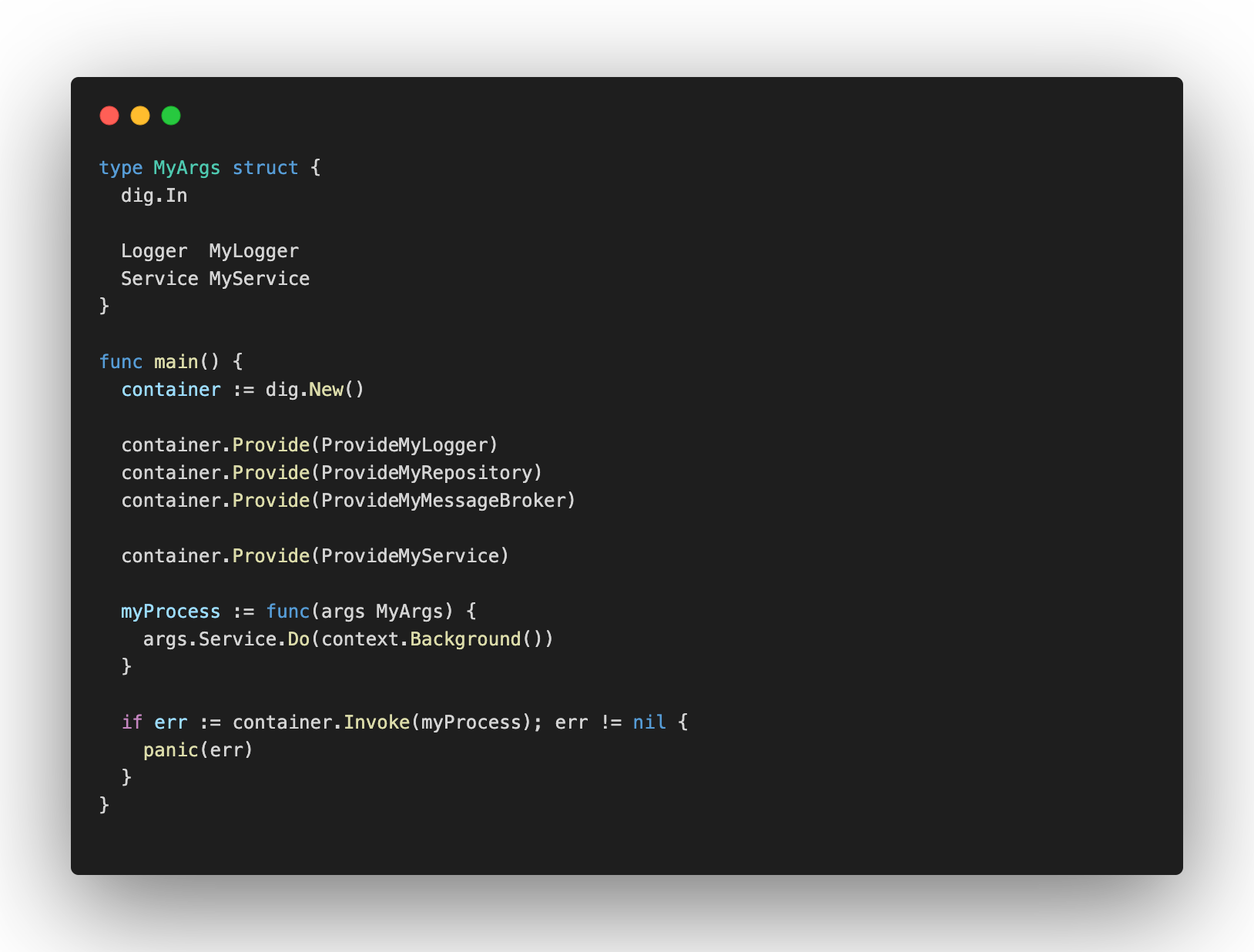
uber-go/dig also supports** Property Injection**, this strategy allows you to create modules of your base dependencies. Every service needs some logging configuration, some database connection, messages brokers, a cloud provider client and etc. You could abstract these kinds of dependency to an internal library of your company, and let your services provide just their own dependencies. It’ll remove a lot of duplicated code from your microservices. To do it, you need to create a struct with dig.In embedded, it’ll say to the container that it must fill all properties with the values you provided. In the example below, when the container tries to create MyArgs it’ll see dig.In is embedded on it, so it’ll set the value you provided in Service and Logger properties.
Conclusion
If you’re looking for an easier way to manage the dependencies in your code, I’m sure that uber-go/dig may be a good option for you. But be aware that it’s a toolkit that makes a lot of dirty work for you, so when another engineer looks at your code for the first time she/he’ll feel that a lot of magic is happening on it, and really is. Also, I think it improves the experience of your engineering team. It removes from them boring refactors. Let’s imagine you need to add a new dependency into a Service/Use Case, you would need to refactor everything that calls its constructor (unit tests, main, etc). A container could help you with this stuff. So the team can stop refactoring unnecessary code and focus on what really matter.
After some years working with Golang, uber-go/digwas the best option I found for this kind of problem. It makes easier the setup process of your service, it makes it clean. The manual style is always an option, but when you have complex dependencies it just gets harder to deal with and when you have multiple services with similar dependencies you probably will copy/paste code between them. It’s not the end of the word, it works fine. But for a growing-up platform, it’s good to have some patterns around it to keep things going in the same way.